Keyword [Facial Action Units]
Linh Tran D, Walecki R, Eleftheriadis S, et al. DeepCoder: Semi-Parametric Variational Autoencoders for Automatic Facial Action Coding[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3190-3199.
1. Overview
人脸表情可以编码成一系列的面部活动单元(facial action units, AUs)及其对应的活动强度(intensity). 而变分自编码器(VAE)能够通过无监督学习(重构loss+KL loss)提取数据的隐含表达(latent representation)。因此,对于人脸AU强度估计的任务可分为两个步骤
- 利用VAE提取人脸特征
- 使用分类器对特征进行AU活动强度估计
另一方面,non-parametric方法(如Gaussian Process)的效果优于parametric,但该方法只适用于小样本数据,无法很好地处理大样本数据。因此,论文将两者进行结合,提出semi-parametric的DeepCoder框架
- parametric VC-AE (Variational Convolutional AEs)
- non-parametric VO-GPAE (Variational Ordinal GP AEs)
并在DISFA和FERA2015数据集上进行实验验证。


1.1. FACS
Facial Action Coding System 定义30多个面部肌肉活动单元,及其活动强度评分标准。
2. 框架结构
2.1. VC-AE
包含两部分loss
- KL loss (Z0)
- reconstruction loss (x->Z0->x’)
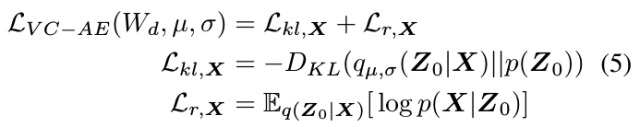

实验中使用warming strategy, 额外加入了AU强度估计loss

2.2. VO-GPAE
包含三部分loss
- KL loss (Z0)
- reconstruction loss (Z0->Z1->Z0)
- 强度估计loss (Z1->Y)

2.3. Joint Learning
Loss function
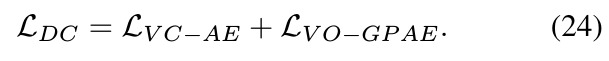
VO-GPAE中的covariance function计算量会随着数据量的增多而增加,因此论文提出leave-subset-out策略,将训练集X分为不相交的两个子集X_R和X_L. X_R用于训练VC-AE, X_L用于训练VO-GPAE, 且X_R>>X_L.
3. Experiments
- NLPD negative log-predictive density for reconstruction error
- ICC intra-class correlation, agreement between annotators

在Z1空间中模型将每个点都fit到一个独立的cluster中,从而使得对Z1空间上的特征进行AU强度估计效果更好。
