Keyword [Facial Action Units] [Valence-Arousal space]
Chang W Y, Hsu S H, Chien J H. Fatauva-net: An integrated deep learning framework for facial attribute recognition, action unit (au) detection, and valence-arousal estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop. 2017.
1. Overview
目前人脸表情识别的两种主流方式为
- Action Units (AUs)
- Valence-Arousal space (V-A space)
结合上述两种方式,论文提出一种能够同时用于
- 人脸属性识别
- AU检测
- V-A估计
3种任务的集成深度学习框架FATAUVA (Facial Attribute Recognition, Action Unit Detection, Valence-Arousal Estimation)。
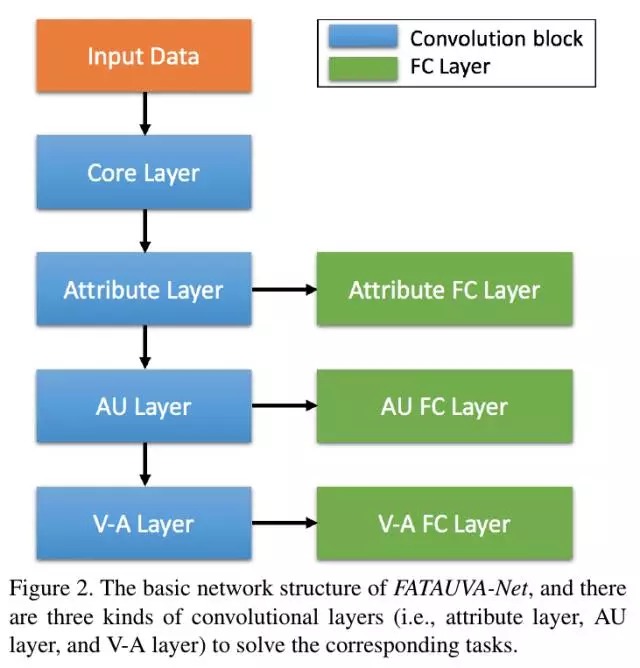
在FATAUVA框架中
- 将Attribute层的输出作为中间特征,用于后续AU检测
- 将AU层的输出作为中间特征,用于后续V-A估计
1.1. 训练过程
- 利用CelebA数据集训练Core Layer和Attribute Layer
- 固定Core Layer和Attribute Layer权重, 利用FERA2015数据集训练AU Layer
- 固定Core Layer, Attribute Layer和AU Layer权重,利用AFF-Wild Challenge训练V-A Layer
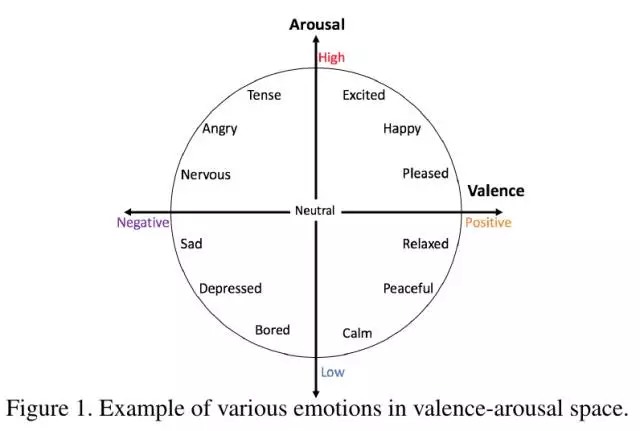
1.2. V-A space
分为两个维度
1.3. 相关数据集
- cross-age celebrity dataset (CADA)
- [Attribute] CelebA
- [AU] FERA2015,
- [AU] BP4D (Video)
- [AU] SEMAINE (实验环境Image)
- [V-A] AFF-Wild Challenge 训练集共253个视频,每帧都有标注;测试集47个视频

2. 网络结构
2.1. Attribute Layer
分为四个子层:Face、Eye、Eyebrow、Mouth
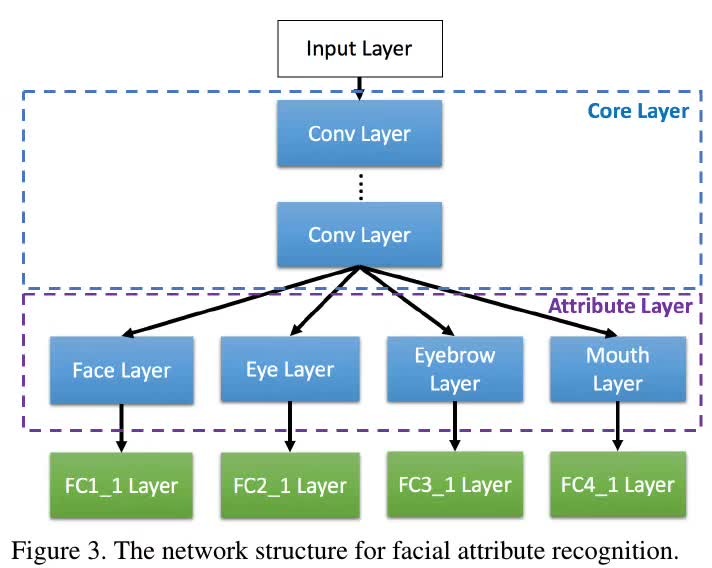
论文从CelebA数据集中选出10种人脸属性,并将这10种属性归属到最相关子层代表的区域中(通过在子层后连接相应的2-way FC层进行预测,每种属性对应一个FC层)。

2.2. AU Layer
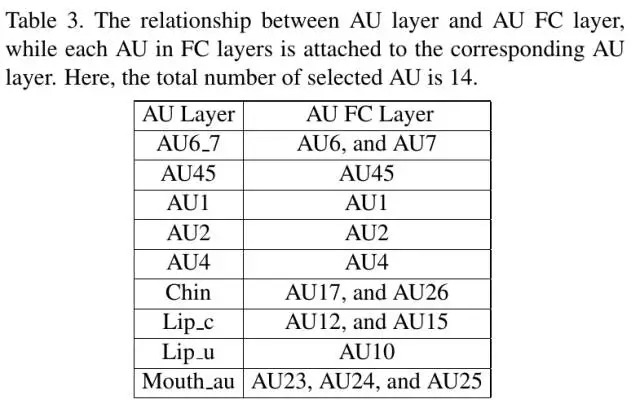
将AUs归属到最相关的Attribute子层代表的区域中(通过在子层后连接相应的AU Conv层,并连接2-way FC层进行预测)。
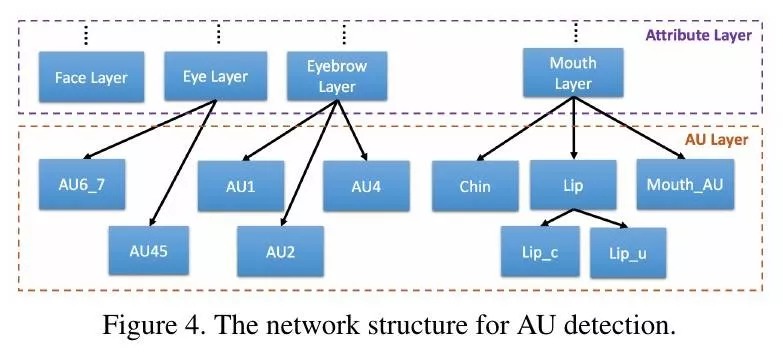
2.3. V-A Layer
将AU分为两组(Valence和Arousal),每组AU concat在一起,输入后续Conv层以及FC层。

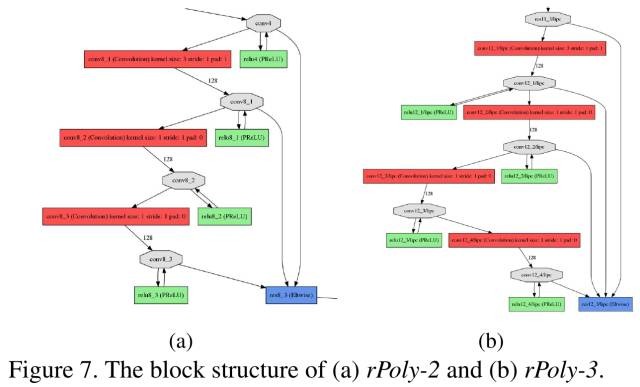
2.4. Convolutional Block
使用PolyNet中的块结构
- Core Layer 8 rPoly-2 blocks
- Attribute Layer 2 rPoly-2 blocks
- AU Layer 2 rPoly-3 blocks
- V-A Layer 2 rPoly-3 blocks
3. Experiments
3.1. 数据预处理
- Attribute和AU数据集 使用MTCNN截取人脸区域
- V-A数据集 使用数据集给定的bounding box截取人脸区域
对每个AU的预测是一个二分类问题。由于正负样本比例不平衡,实验对较少的AU进行over sampling,对负样本进行down sampling.
将V-A得分量化到[-5,5]范围,进行可视化
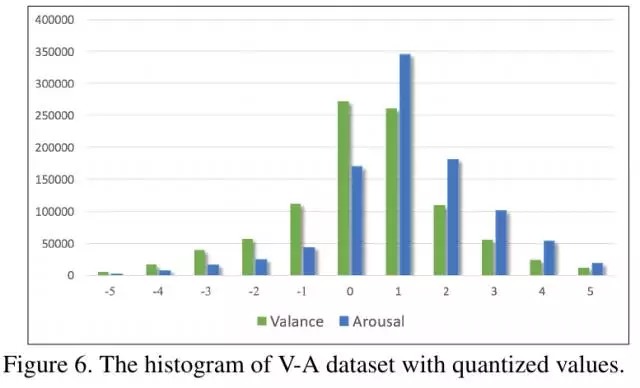
由于样本分布不平衡,实验同样进行over sampling和down sampling.
3.2. Loss Layer
在Attribute Layer和AU Layer后连接3层FC,最后对2维输出做softmax操作。
在V-A Layer后连接3层FC,并使用了两种loss
- class-based 将[-5, 5]范围的得分离散化为11种类别。选择top 3得分:(1)如果得分连续(1,2,3或1,3,2),进行加权求和得到最终得分。(2)如果得分不连续,取top 1得分作为最终得分。
- regression-based 结合center loss和smooth L1 loss
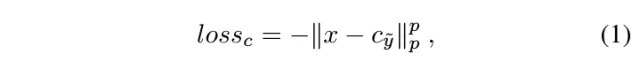
- x 倒数第二层FC输出的特征
- c 类别y的中心(倒数第二层FC输出对应类别y的特征的均值)
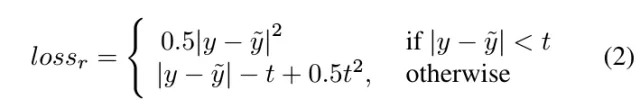
- y 预测值
- y^{~} ground truth
- t L1与L2之间的转折点
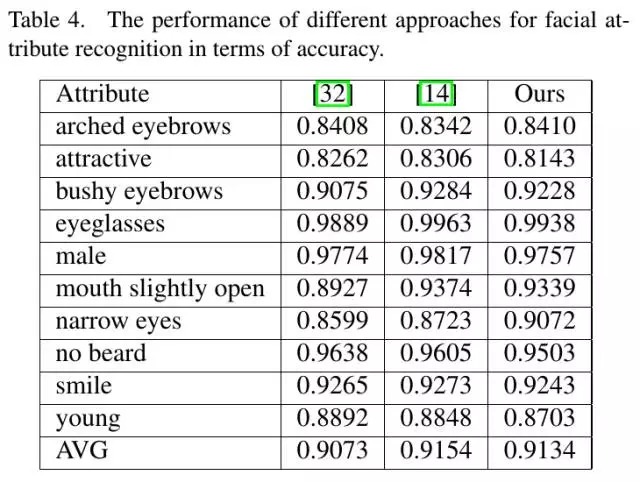
3.3. Attribute Recognition实验结果
3.4. AU Detection实验结果

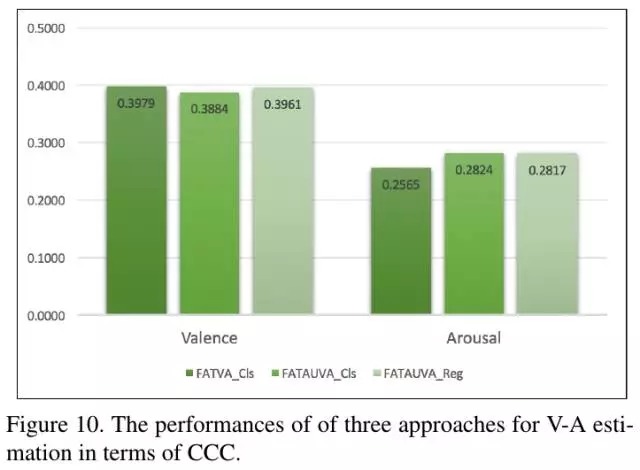
3.5. V-A Estimation实验结果
- 使用AU能够提高V-Aestimation结果
- 使用regression-based loss优于class-based loss
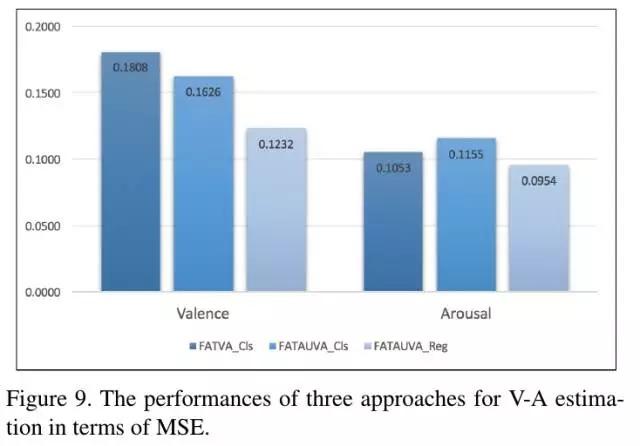
CCC: Concordance Correlation Coefficient