Li J, Chen B M, Hee Lee G. So-net: Self-organizing network for point cloud analysis[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 9397-9406.
1. Overview
1.1. Motivation
- The computation of rasterizing 3D data into voxel
- Point cloud can be easily acquired with popular sensor (RGB-D, LiDAR, camera with the help with Structure-from-Motion)
- PointNet. can not handle local feature extraction
- PointNet++. not reveal the spatial distribution of the input cloud
- Kd-Net. lack of overlapped receptive fields
In this paper, it proposde So-Net
- model the spatial distribution of point cloud by Self-Organizing Map (SOM)
- overlapped receptive field. conducting by point-to-node KNN search
- hierarchical feature extraction
- permutation invariant
- Experiments. reconstruction, classification, part segmentation, shape retrieval
1.2. Contribution
- explicity utilize the spatial distribution of point cloud
- overlapped receptive field
- pre-trained point cloud autoencoder
- faster speed
1.3. Related Work
- voxel grid
- orientation pooling
- project 3D into 2D
- VAE
- sparse method
- sepctral ConvNet
- render 3D into multi-view 3D and view-pooling
- Kd-Net
- PointNet (++)
1.4. Dataset
- MNIST
- ModelNet10, ModelNet40
- ShapeNetPart
2. So-Net
2.1. Permutation Invariant SOM
- produce 2D representation of input point cloud. m x m nodes, m∈[5, 11]
- unsupervised trained
2.1.1. The reason of not permutation invariant
- training result highly related to the initial nodes
- per-sample update rule depends on the order of the input points
2.1.2. Solution
fixed initial nodes. disperse the node uniformly inside a unit ball
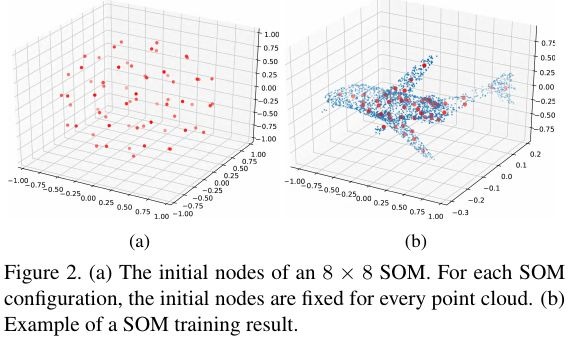
batch update (matrix operation highly efficient on GPU). based on all points, instead of once per point
2.2. Encoder
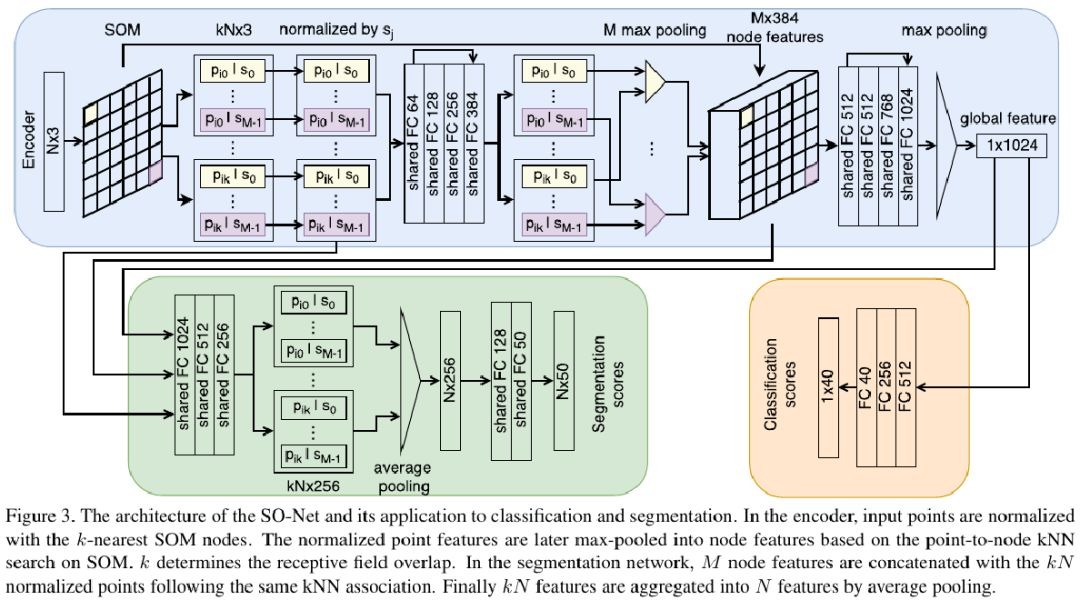
given the ouput of SOM, for each point p, seach KNN SOM nodes s
- N input points
- M nodes
- kN points (k control the overlapped)
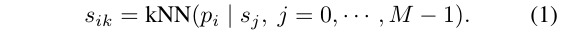
normalize each point based on it’s node
- kN normalized points
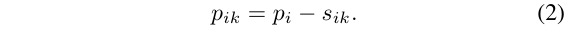
- kN normalized points
processed by shared FCs
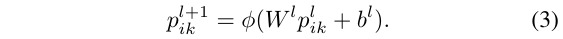
maxpool each M mini clouds
M points
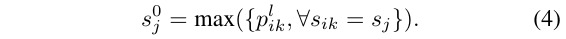
2.3. Feature Aggregation
- point feature→ node feature
- node feature→ global feature
2.4. Isolated Node outside the Point Cloud
- set node features to zero
2.5. Segmentation
- combine the point, node and global features
- found middle fusion with avg pooling is effective
2.6. AutoEncoder

- stacking series of FC will heavy memory and computation, if point is large
- contains FC branch (details) and Conv branch (main body)
- upconv. 3x3 Conv + NN upsample (more effective than DeConv)
- conv2pc. 1x1 Conv + 1x1 Conv
- coarse-to-fine
- Chamfer loss. point number between input and output need not equal

P_s, P_t: input and recovered cloud
3. Experiments
3.1. Details
- 8x8 SOM; k=3
- batch size 8
- each layer followed by (BN + ReLu)
3.2. Dataset Augmentation
- Gaussian Noise (0, 0.01) to point coordinate and surface normal vectors
- Gaussian Noise (0, 0.04) to SOM node
- scaling point clouds, surface normal vectors and SOM node by a factor from an uniform distribution (0.8, 1.2)
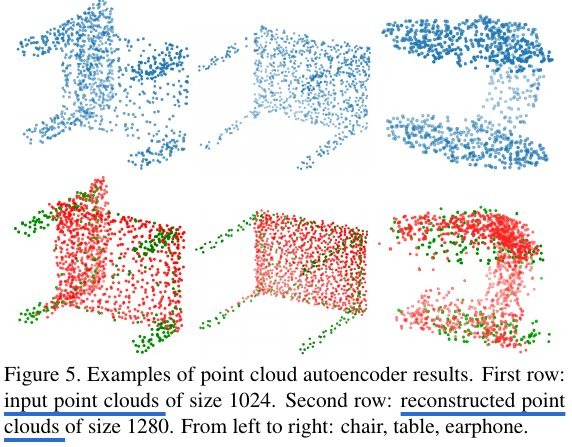
3.3. Reconstruction
3.4. Classification

- pre-trained can improve accuracy
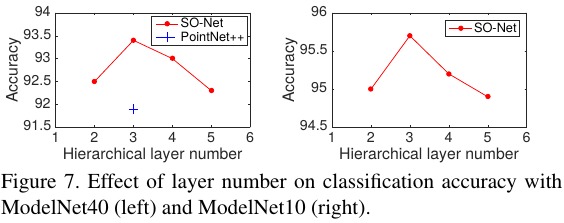
- overfitting when too many layers (SOM grouping + PointNet)
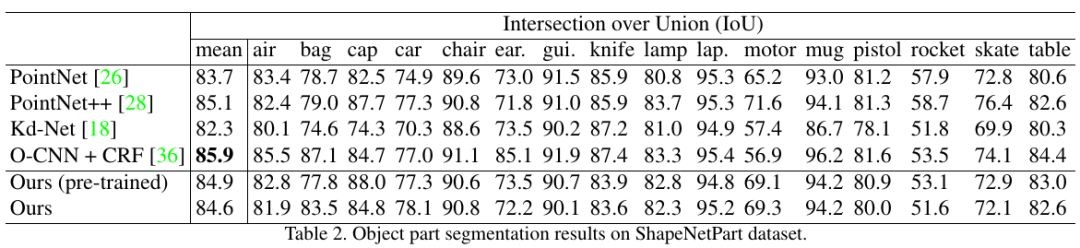
3.5. Segmentation