Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems. 2017: 6000-6010.
1. Overview
1.1. Motivation
- dominant sequence transduction models based on RNN or CNN
- RNN can not parallel, computational complexity, hard to learn long-range dependencies

In this paper, it proposed Transformer based solely on attention mechanism
- without regard to their distance
- attention to achieve global dependencies
1.2. Related Work
- reduce sequential computation
- self-attention (intra-attention)
- end-to-end memory network. based on recurrent attention mechanism
2. Methods
- encoder. [x_1, …, x_n]→ [z_1, …, z_n]
- decoder. [z_1, …, z_n]→ [y_1, …, y_m]
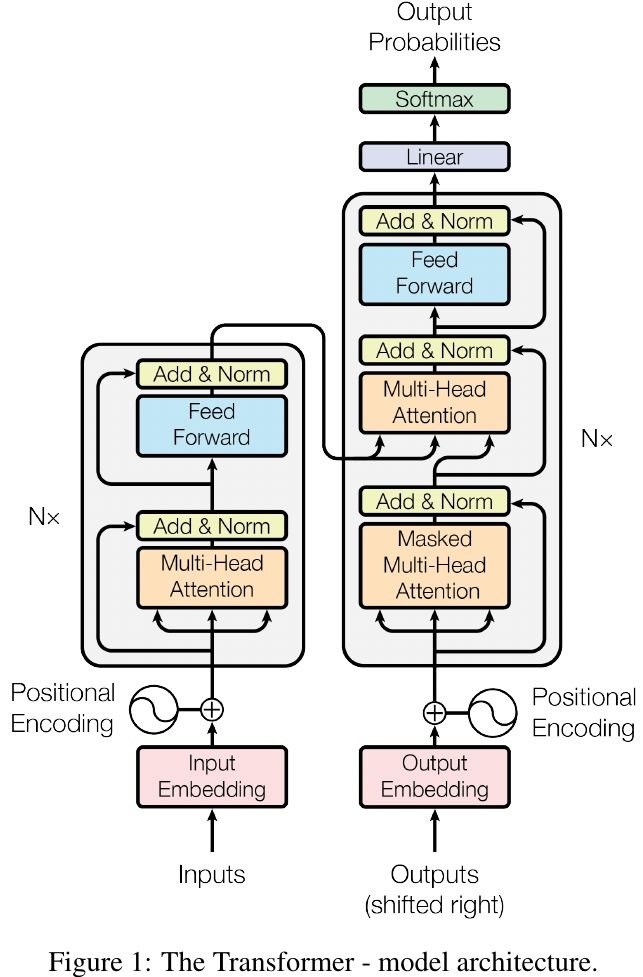
2.1. Encoder
- N = 6
- d_model = 512
- two sub-layers + layer normalizaion + residual
- multi-head self-attention
- position-wise FC feed-forward network
2.2. Decoder
- N = 6
- insert a third sub-layer. perform multi-head attention over the output of the encoder stack
2.3. Attention

2.3.1. Scaled Dot-Product Attention
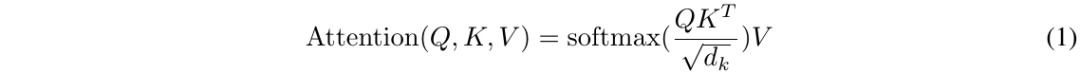
2.3.2. Multi-Head Attention

- h = 8
- d_k = d_v = d_{model} / h = 64
Found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to d_k, d_k and d_v dimensions.
2.4. Multi-Head Attention
- encoder-decoder attention. Q from previous decoder, K-V from final encoder
- self-attention in encoder
- self-attention in decoder
Mask out all value which correspond to illegal connection to prevent leftward information flow in the decoder to preserve the auto-regressive property
2.5. Position-Wise FC

- or 2 1x1Conv
- inner-layer d_{ff} = 2048
- input d_{model} = 512
2.6. Position Encoding
- since no RNN or CNN, need to inject information about the token’s position
- use sine and cosine function

3. Experiments
3.1. Details
- sentence encoded by byte-pair encoding
- sentence pairs were batched together by approximate sequence length
Adam; LR increase linearly by first warmup_steps then decrease

Dropout 0.1.
3.2. Comparison

3.3. Ablation Study
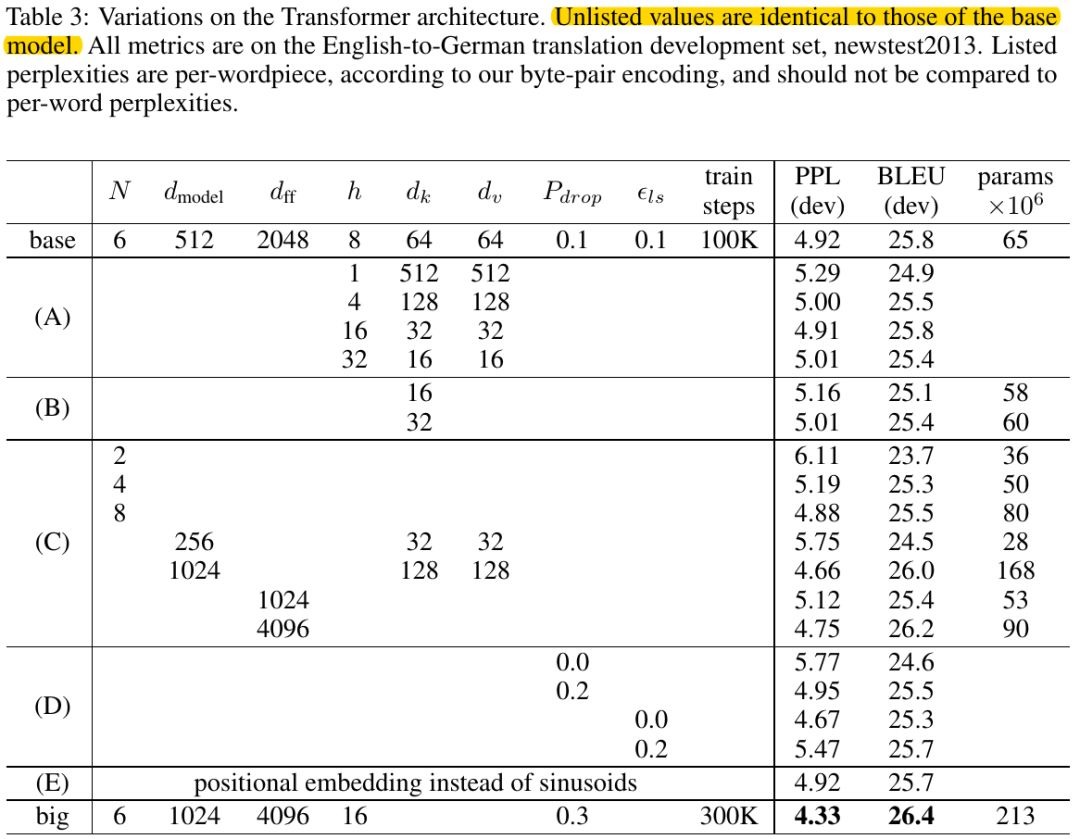
- B. reducing d_k hurts model quality
- C,D. bigger model better, dropout helpful in avoiding over-fitting
- E. position embedding nearly identical to sinusoid