Keyword [Semantic Embedding] [Transfer Knowledge] [GCN]
Wang X, Ye Y, Gupta A. Zero-shot recognition via semantic embeddings and knowledge graphs[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6857-6866.
1. Overview
1.1. Motivation
two paradigms of transferring knowledge
- use implicit knowledge representation (semantic embedding)
- use explicit knowledge bases or knowledge graph
In this paper
- based on Graph Convolutional Network (GCN)
- predict visual classifier for each category
- use both (imexplicit) semantic embeddings and the (explicit) categorical relationships to predict the classifier
1.2. Related Works
- Zero-Shot Learning
- attribute
- semantic embeddings
- knowledge graph
2. Methods
2.1. GCN
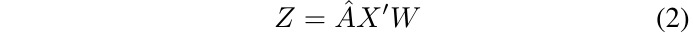
- A [n x n]. normalized, binary adjacency matrix of graph
- X [n x k]. feature matrix
- W [k x c]. weight matrix
- Z [n x c]. output
- n. the number of category; node of hte graph
- ReLU
2.1.1. Training Time

- use first m entities
- X = {x_1, x_2, …, x_n}, n entities embedding
- Y = {y_1, y_2, …, y_n}
- y_i ∈ {1, …, C}
- C. the number of labels
2.1.2. Testing Time
- use n-m entities
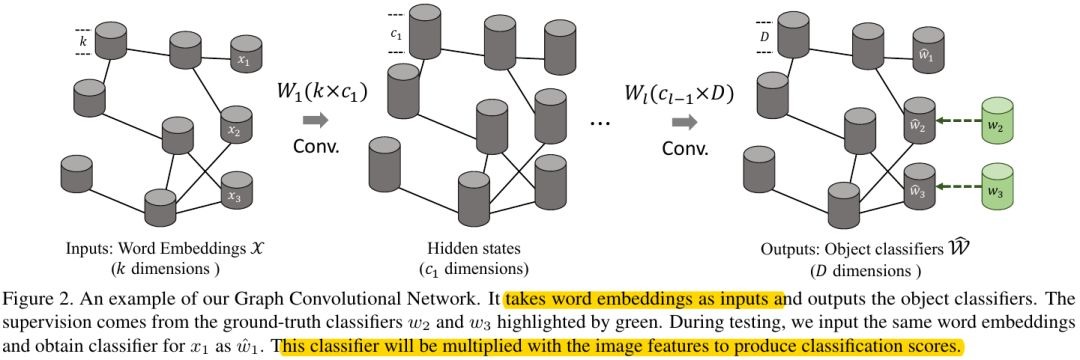
2.2. GCN for Zero-Shot Learning
Input. set of category’s embedding vector
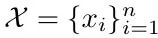
Output. visual classifier for each input category (node)
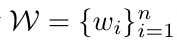
visual feature. extract by fixed pre-trained net, dimension D
- classifier. dimension D for each node
- 6-layer GCN
A direct way. input x_i, output w_i based on m training pairs, but m is small.
2.2.1. Loss function
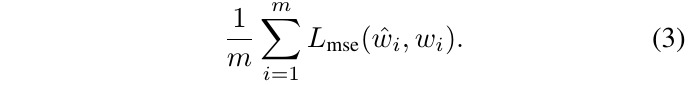
- ground-truth classifier weights learned from training images
2.3. Details
- LeakyReLU (0.2) leads to faster convergence
- L2-Normalized classifier is important
- find the last layer classifiers of the ImageNet pre-trained networks are naturally normalized
3. Experiments
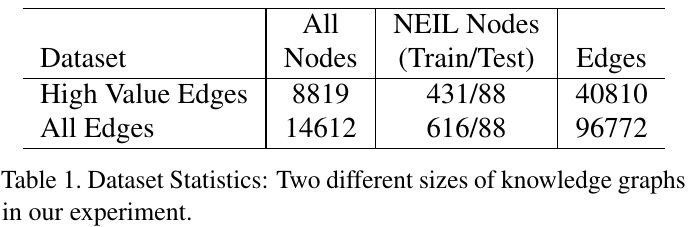
3.1. Dataset
- relationships and graph (common sense knowledge rules) from Never-Ending Language Learning (NELL)
- images from Never-Ending Image Learning (NEIL)
- construct a new knowledge graph based on NELL and NEIL (1.7M object entities, 2.4M edges)
- use Breadth-first search (BFS), maximum length 7 hops
3.2. Ablation Study
3.2.1. Baseline
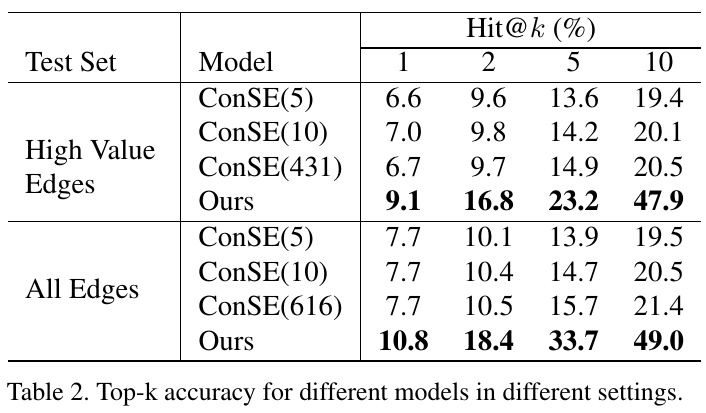
- more performance gain as our graph size increases
3.2.2. Missing Edge

- knowledge graph chave redundant information with 14k nodes and 97k edges connecting them
3.2.3. Random Graph
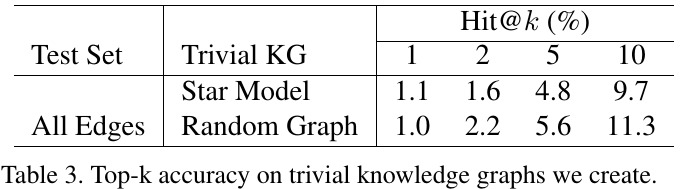
3.2.4. Depth of GCN
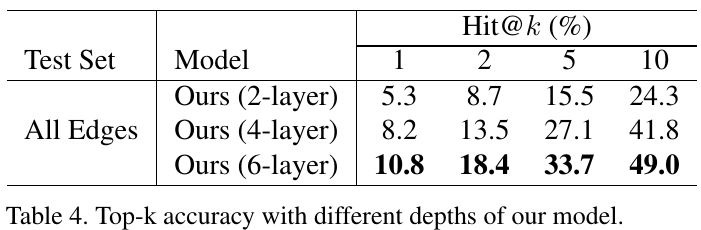
- optimization becomes harder as the network goes deeper
3.2.5. Differences between Word Embeding and Classifier
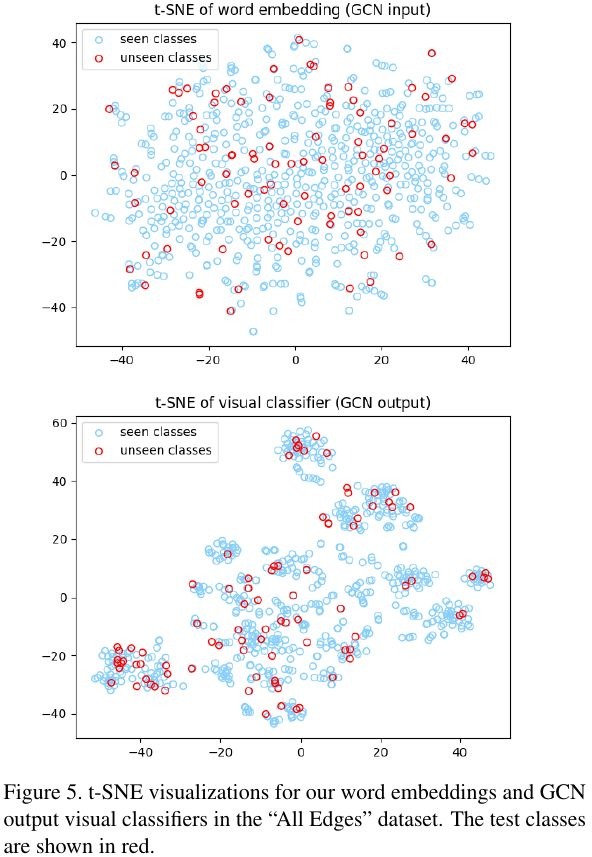
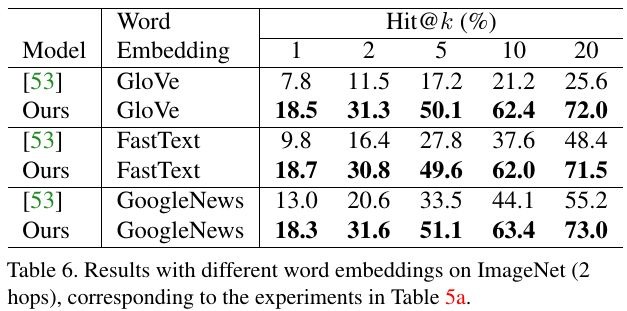
3.2.6. Is Word Embedding Methods Crucial
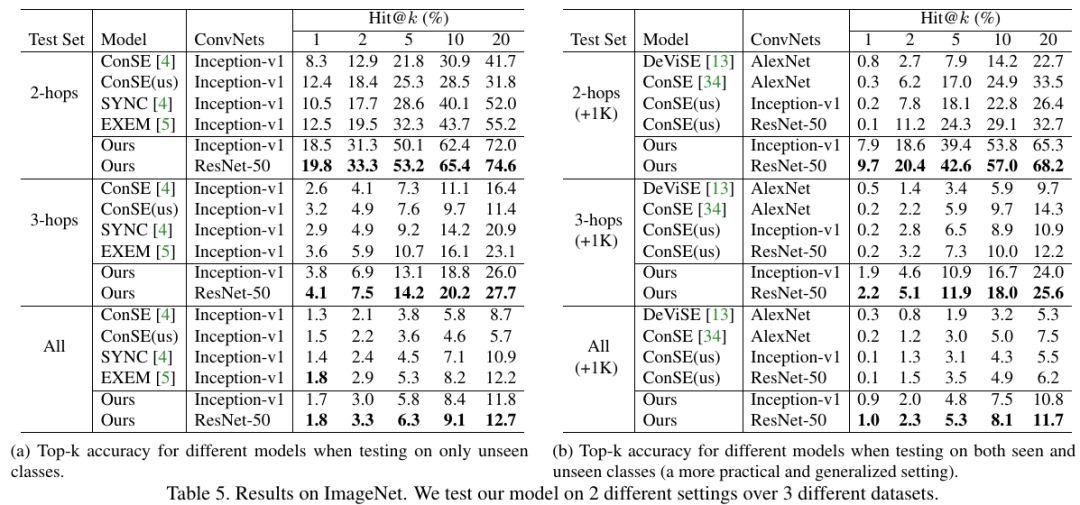
3.3. Comparison