Keyword [Bi-LSTM] [Matching Net] [Attention LSTM]
Vinyals O, Blundell C, Lillicrap T, et al. Matching networks for one shot learning[C]//Advances in neural information processing systems. 2016: 3630-3638.
1. Overview
In this paper, it proposes Matching Nets (MN)
- maps a small labeled support set and an unlabeled example to its label
- based on Bi-LSTM and Atten-LSTM
- experiments on vision (Omniglot, ImageNet) and language (Penn Treebank)
- devise new data set. miniImageNet (60,000 images, 84x84, 100 classes, 600 examples/class)
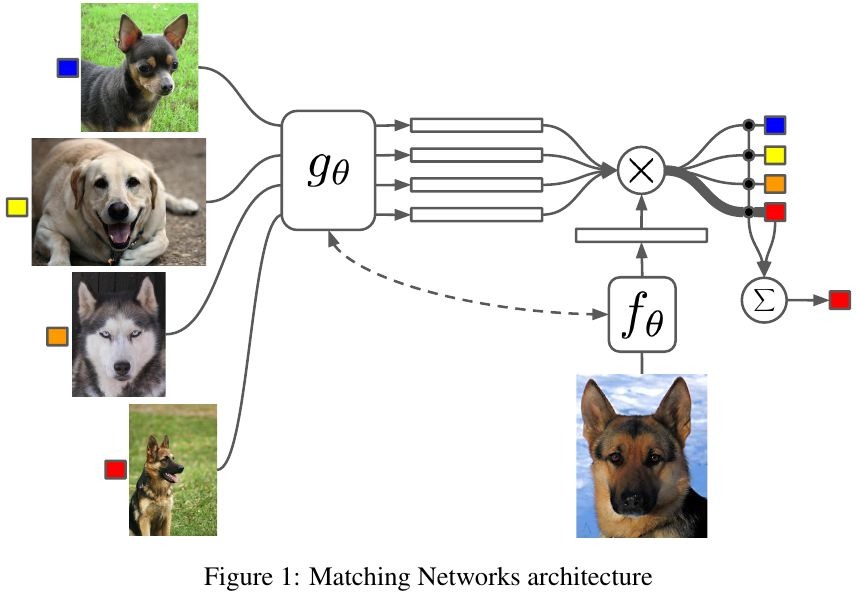
1.1. Model
1.1.1. Basic Formulation

- x_i, y_i. labeled small support set
- a. attention mechanism
1.1.2. Attention Kernel

- g, f. embedded function
- c. cosine similarly
- x^. query image
1.1.3. Full Context Embeddings

bi-LSTM

S should be able to modify how to embed the test img x^ through f
- K. number of unrolling steps of LSTM
1.2. Loss Function
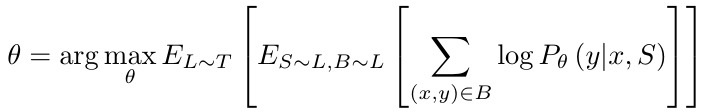
1.2.1. Training
- for each episode, sample L labels
- sample support set S and query set B
1.2.2. Testing
- know support set S’
- predict label of query set B’
1.3. Network
- 4 Conv
- [64, 3x3 Conv; BN; ReLU; Maxpool]
1.4. Experiments
Omniglot

ImageNet
