Ye L, Rochan M, Liu Z, et al. Cross-Modal Self-Attention Network for Referring Image Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 10502-10511.
1. Overview
1.1. Motivation
1) existing methods treat language expression and image separately
2) not sufficiently capture long-range correlations between these two modalities
In this paper, it proposes
1) cross-modal self-attention (CMSA)
2) gated multi-level fusion module

1.2. Dataset
- UNC
- UNC+
- G-Ref
- ReferIt
2. Model
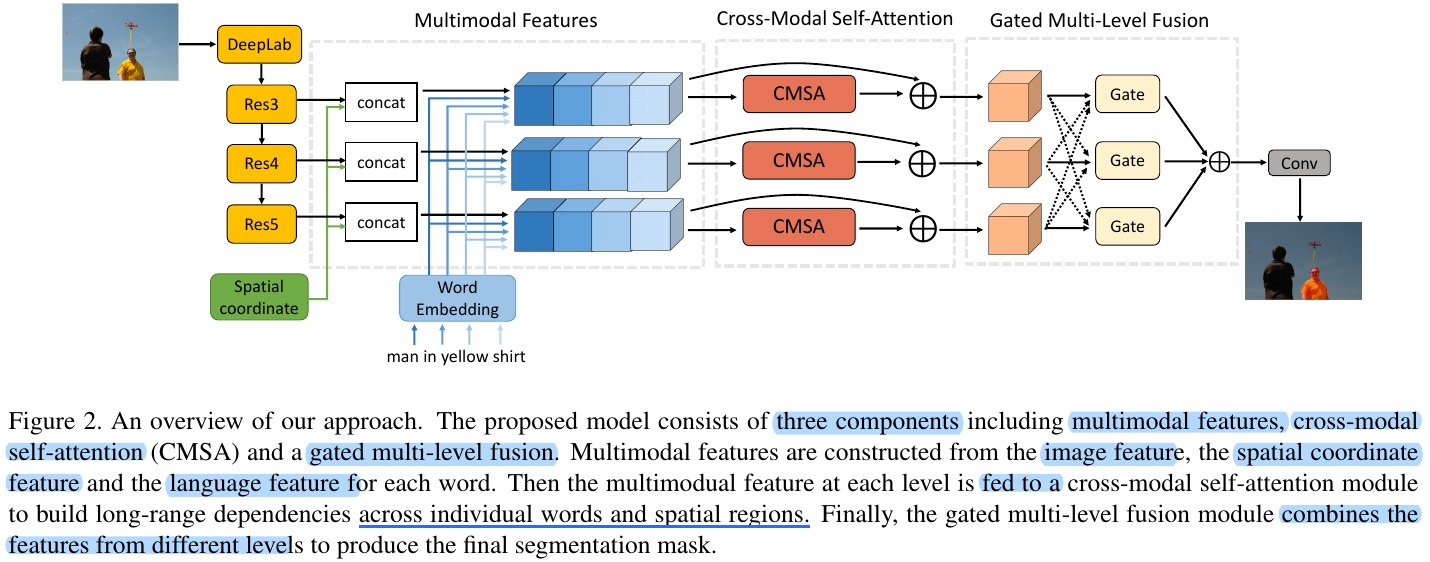
2.1. Multimodal Features

Concate visual feature, spatial feature and word feature. $N×H×W×(C_v+C_l+8)$
1) $p$. $p$-th visual point
2) $n$, $n$-th word
3) $s_p$. 8-D spatial feature: (3 normalized horizontal positions, 3 vertical, height, width)
2.2. Cross-Modal Self-Attention

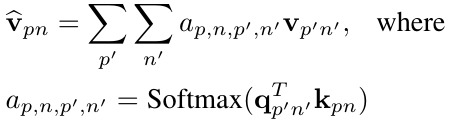

1) $a_{p,n,p’, n’}$. attention weight between feature $f_{pn}$ and $f_{p’n’}$
2) $q_{pn}=W_qf_{pn}$, $k_{pn}=W_kf_{pn}$, $v_{pn}=W_vf_{pn}$
3) $W_q, W_k, W_v∈R^{512×(C_v+C_l+8)}$
2.3. Gated Multi-Level Fusion
Fusing features at multiple scales can improve the performance of referring image segmentation.


1) memory gate $m^i$
2) reset gate $r^i$
3) $m^i, r^i∈R^{H_i×W_i}$
3. Experiments
