Keyword [ShuffleNetv2]
Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 116-131.
1. Overview
1.1. Motivation
1) Architecture design is mostly guided by the indirect metric of computation complexity, such as FLOPs.
2) Direct metric (such as speed) also depends on other factors, such as memory access cost and platform characterics.
In this paper, it proposed ShuffleNet V2
1) Evaluate the direct metric on target platform, beyond FLOPs.
2) Four practical guidelines for efficient network design.
3) ShuffleNet V2 is much faster and more accuracy
2. FLOPs vs Speed

1) MobileNetV2 is much faster than NASNET-A, but they have comparable FLOPs.
2) FLOPs metric only account for Conv part. The other operations include:
- Data I/O
- Data shuffle
- Element-wise operations, such as AddTensor, ReLU

Two reasons
1) Several factors affecting speed are not taken into account by FLOPs.
- Memory Access Cost (MAC). Such as group conv.
- Degree of Parallelism. A model with higher degree of parallelism is faster than lower one, under the same FLOPs.
2) Operations with the same FLOPs could have different running time.
- Decomposition in GoogleNet is slower on GPU, although it reduces FLOPs by 75%. As the lastest CUDNN library is specially optimized for $3 \times 3$ conv.
- It can not think that $3 \times 3$ conv is 9 times slower thab $1 \times 1$ conv.
3. Practical Guidelines for Efficient Network Design
Environment
1) GPU. A single NVIDIA GeForce GTX 1080Ti with CUDNN 7.0.
2) ARM. A Qualcomm Snapdragon 810.
3.1. Equal Channel Width Minimizes Memory Access Cost (MAC)

A benchmark network is built by stacking 10 blocks. Each block contains two Conv (c1→
c2, c2→c1).
Against
1) Inverted Bottleneck structure of MobileNet V2.
2) Bottleneck-like buiding blocks of ShuffleNet V1.
3.2. Excessive Group Conv Incrases MAC

1) MAX increases with the growth of $g$.
2) Group number should be carefully chosen based on the target platform and task.
Against
1) Group Conv of ShuffleNet V1.
3.3. Network Fragment Reduces Degree of Parallelism


Fragment. The number of individual Conv or pooling operations in one building block
Against
1) Auto-generated structures
3.4. Element-wise Operations are Non-negligible

ReLU, AddTensor and AddBias have small FLOPs but relatively heavy MAC
Against
1) Depthwise Conv and ReLu on thick feature maps of MobileNet V2
4. ShuffleNet V2
4.1. Block
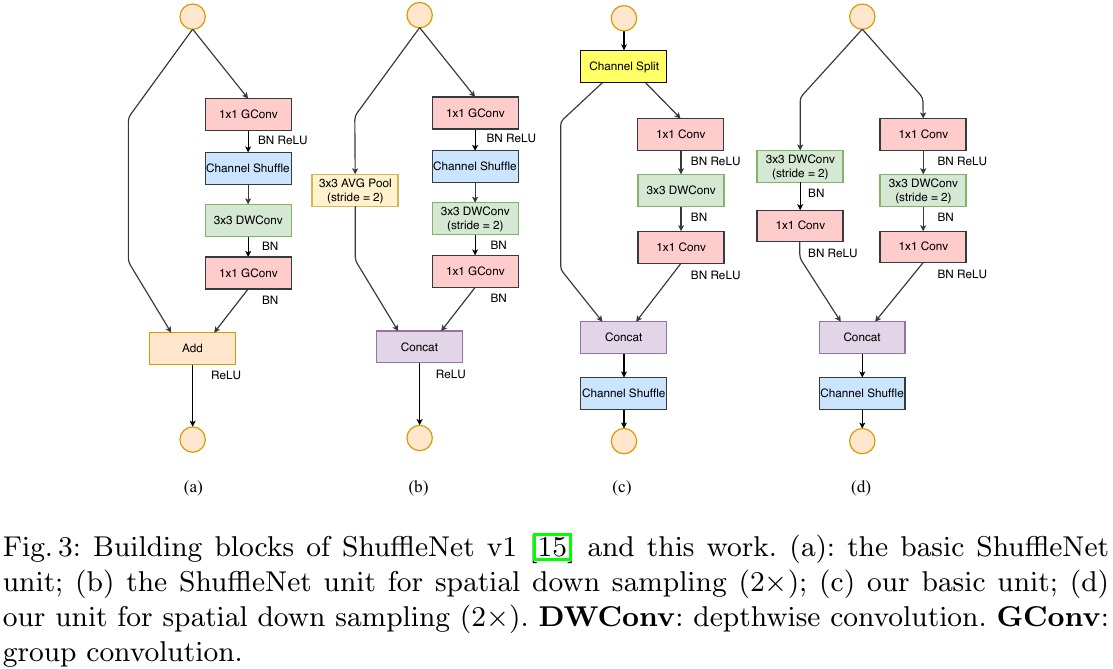
1) Channel Split. $c-c^’$ and $c$. In this papaer, $c^’ = c/2$
2) Two $1 \times 1$ Conv are no longer group-wise. As split operation already produces two groups
3) One single element-wise operation. (Concat + Channel Shuffle + Channel Split)
4.2. Architecture

4.3. Larger Architecture

