Keyword [Classification] [EM Algorithm]
Hui J. Understanding Matrix capsules with EM Routing[J]. Blog. Nov, 2017.
“Understanding Matrix capsules with EM Routing (Based on Hinton’s Capsule Networks)”
1. Overview
1.1. 向量capsule缺陷
此前提出的capsule结构存在一些缺陷
- 利用pose向量的长度表示存在概率时,使用了squash函数将向量长度压缩至[0, 1],这阻碍了一些有意义的目标函数的使用。
- 使用余弦角度测量两个pose向量之间的agreement,不能很好地区分quit good agreement和very good agreement. 而使用Gaussian cluster能使实现这点。
- 对于长度为n的pose向量,其变换矩阵有n*n个参数。而对于n个元素的pose矩阵,其变换矩阵只有n个参数。
1.2. 矩阵capsule结构
因此,本文提出一种新的capsule结构,其中包含
- a logistic unit,表示该entity存在概率。
- a 4*4 pose矩阵,通过学习表示entity与viewer之间的关系。
L层某个$capsule_i$的pose矩阵乘以viewpoint-invariant变换矩阵得到的结果为$capsule_i$对L+1层各$capsule_c$的pose矩阵的vote. Viewpoint-invariant变换矩阵通过学习能够表示part-whole关系。
每个vote都对应一个权重系数$r_i$,权重系数通过EM算法迭代更新。在本文中使用的迭代次数为3.
矩阵capsule结构在smallNORB数据集上相对于目前的state-of-the-art减小了45%的test errors. 并且更能够抵抗白盒对抗攻击。
2. Introduction
2.1. Viewpoint与Pose矩阵
- Viewpoint的改变会导致图像像素产生较大的变化,但对表示objet和viewer之间关系的pose矩阵而言,只会产生简单的线性影响。
- 随着viewpoint的改变,pose矩阵以一种协调的方式进行变化,因此不同部位votes的agreement保持恒定。

2.2. 反向Attention
由L+1层的所有$capsule_c$竞争L层的某个$capsule_i$,即权重系数和为1. 而正向Attention是由L层的所有$capsule_i$竞争L+1层的某个$capsule_c$。

3. EM迭代路由算法
将L层各capsule_i看为一个data point,L+1层各$capsule_c$看为一个Gaussian模型。因L层各$capsule_i$的vote路由问题转化为对给定数量data point进行Gaussian聚类问题。例如,眼睛、鼻子、嘴巴的$capsule_i$都vote(聚成一个cluster) L+1层中某个$capsule_c$,即检测到人脸。

3.1. 计算公式
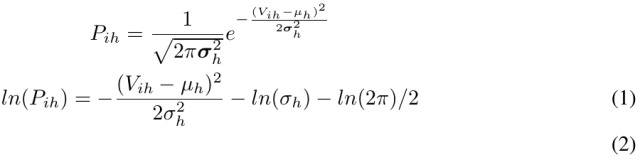
cost表示某个$capsule_i$属于$caps_c$的一部分的概率。cost越低,则属于的可能性越大。
λ为超参数,b为描述$capsule_c$均值的cost,可学习。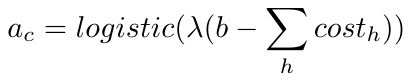
3.2. EM路由算法

- 实验中设置的迭代次数为3.
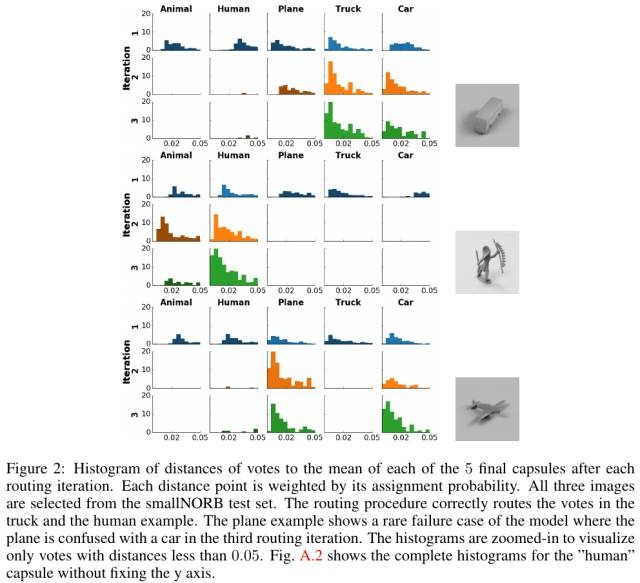

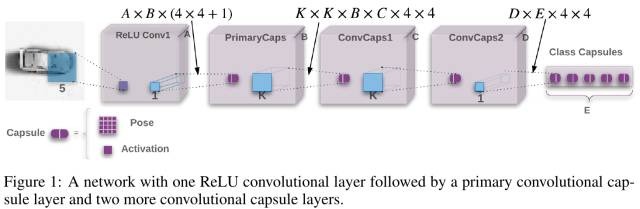
4. Capsule模型

4.1. ReLU+Conv1
- 5*5 kernel, 32 channel (A=32), stride 2.
- 输入: (b, c, 32, 32)
- 输出: (b, 32, 14, 14 )
4.2. PrimaryCaps
- 1*1 kernel, 32 channel (B=32), stride 1.
- 输入: (b, 32, 14, 14)
- 输出: (b, 32, 14, 14, 17)
4.3. ConvCaps1
- 3*3 kernel (K=3), 32 channel (C=32), stride 2.
- 输入: (b, 32, 14, 14, 17)
- 输出: (b, 32, 6, 6, 17)
4.4. ConvCaps2
- 3*3 kernel (K=3), 32 channel (D=32), stride 1.
- 输入: (b, 32, 6, 6, 17)
- 输出: (b, 32, 4, 4, 17)
4.5. Class Capsule
- 可看做h*w kernel, 10 channel (分类类别), stride 1. 该层使用了Coordinate Addition方法,额外加入每个感知区域的xy坐标到vote的前两个元素中。
- 输入: (b, 32, 4, 4, 17)
- 输出: (b, 10, 17)
4.6. Spread Loss
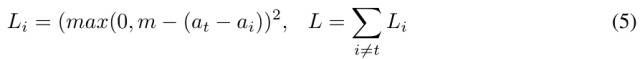
- 最大化目标类别的activation与其他类别activation的差值。m为margin,从0.2开始线性增长,避免dead capsule.
5. Experiments
- samllNORB数据集包含5种类别的玩具图片:飞机、车、卡车
- 人类和动物。每种类别都有18个不同的视角(0-340), 9种高度和6种光照条件。图片大小为9696.实验中将其下采样为4848并做32*32 random crop操作。

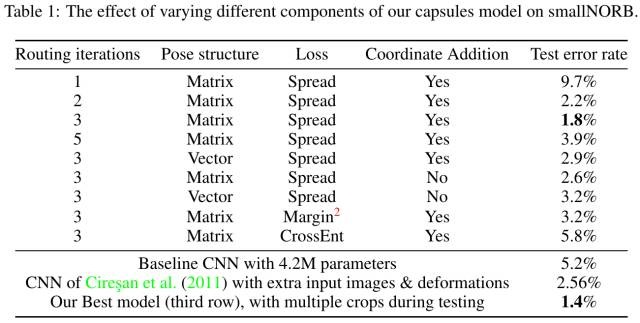
- 更进一步,实验使用训练集不包含的viewpoint进行测试

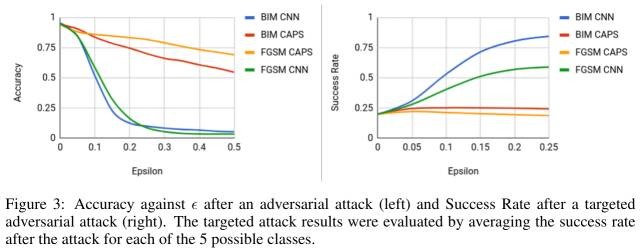
6. 对抗鲁棒性